From Raw Documents to RAG-Ready Data, Simplified
Sutro takes the pain away from preparing data for your Retrieval-Augmented Generation systems. Iterate on your strategy, scale to production, and integrate with your existing stack.
import sutro as so
from pydantic import BaseModel
class ReviewClassifier(BaseModel):
sentiment: str
user_reviews = '.
User_reviews.csv
User_reviews-1.csv
User_reviews-2.csv
User_reviews-3.csv
system_prompt = 'Classify the review as positive, neutral, or negative.'
results = so.infer(user_reviews, system_prompt, output_schema=ReviewClassifier)
Progress: 1% | 1/514,879 | Input tokens processed: 0.41m, Tokens generated: 591k
█░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░
Prototype
Start small and iterate fast on your data preparation workflows. Accelerate experiments by testing different chunking, extraction, or summarization strategies on Sutro before committing to large jobs.
Scale
Scale your LLM workflows to process billions of tokens in hours, not days. Get your data ready for your vector database with no infrastructure headaches or exploding costs.
Integrate
Seamlessly connect Sutro to your existing LLM workflows. Sutro's Python SDK is compatible with popular data orchestration tools, like Airflow and Dagster.

Improve RAG Performance
Improve your RAG retrieval performance by generating high-quality, diverse, and representative synthetic data or by easily converting large corpuses of free-form text into vector representations for semantic search.
Get results faster and reduce costs by 10x or more. Prepare millions of documents for your RAG pipeline by parallelizing LLM calls through Sutro.
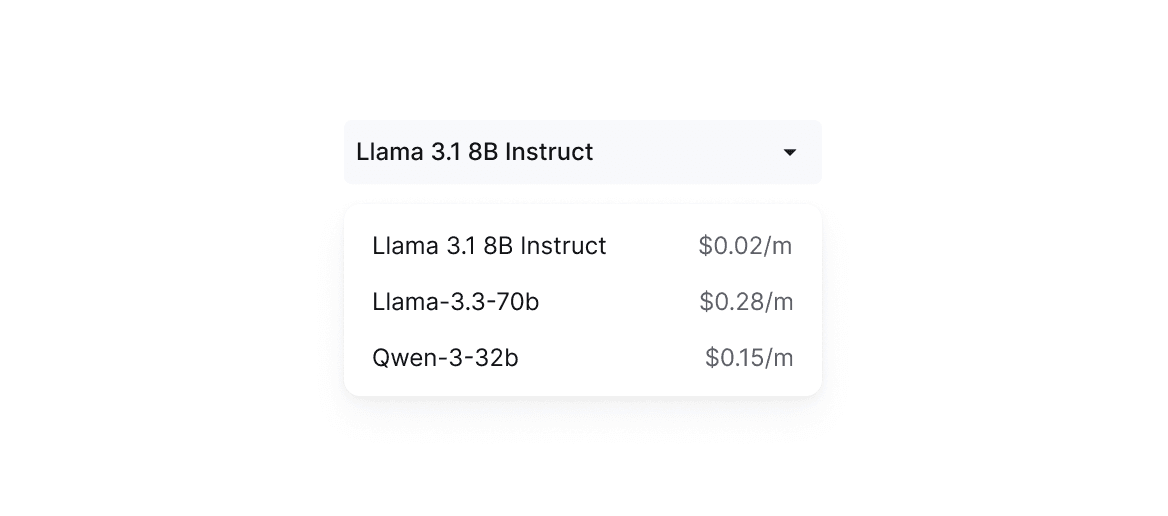
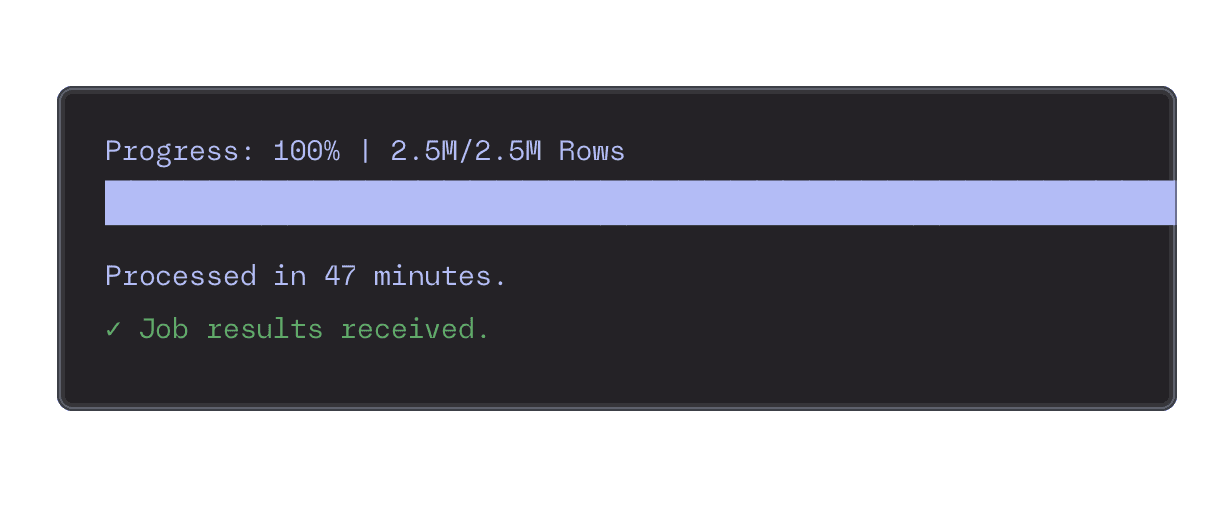
Scale Effortlessly
Confidently process millions of documents and billions of tokens at a time without the pain of managing infrastructure. Scale your data preparation as your needs grow.
