A Simplified Path to Scalable Metadata Generation
Sutro takes the pain away from testing and scaling LLM batch jobs. Start small with a simple Pythonic interface, test your prompts, and scale to millions of files.
import sutro as so
from pydantic import BaseModel
class ReviewClassifier(BaseModel):
sentiment: str
user_reviews = '.
User_reviews.csv
User_reviews-1.csv
User_reviews-2.csv
User_reviews-3.csv
system_prompt = 'Classify the review as positive, neutral, or negative.'
results = so.infer(user_reviews, system_prompt, output_schema=ReviewClassifier)
Progress: 1% | 1/514,879 | Input tokens processed: 0.41m, Tokens generated: 591k
█░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░
Prototype
Start small and iterate fast on your metadata extraction workflows. Accelerate experiments by testing on a sample of your data before committing to large jobs.
Scale
Scale your metadata workflows to process billions of tokens in hours, not days. Do more in less time with no infrastructure headaches or exploding costs.
Integrate
Seamlessly connect Sutro to your existing data workflows. Sutro's Python SDK is compatible with popular data orchestration tools, like Airflow and Dagster.

Scale Effortlessly
Confidently handle millions of documents and billions of tokens at a time. Sutro processes large-scale metadata generation jobs without the pain of managing infrastructure.
Get results faster and significantly reduce costs by parallelizing your LLM calls through Sutro's batch processing API, turning a major expense into a manageable one.
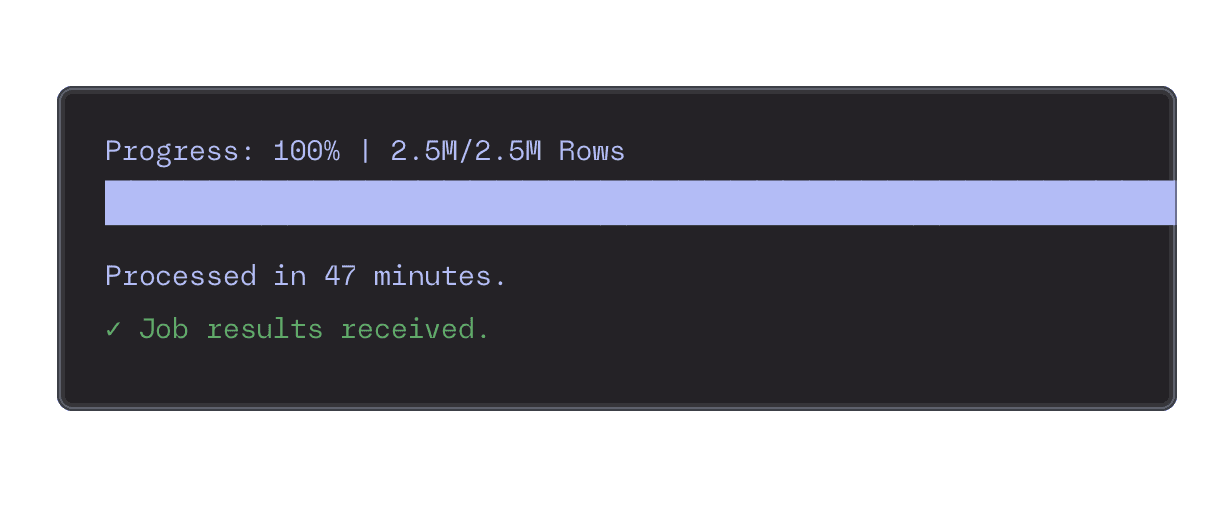
From Raw Data to Actionable Insights, Faster
Shorten data processing cycles from days to hours. Go from massive amounts of free-form text to analytics-ready datasets that drive business decisions.
