From Raw Text to Production Summaries
Sutro simplifies the entire workflow for large-scale document summarization, from initial testing to full deployment in your existing data stack.
import sutro as so
from pydantic import BaseModel
class ReviewClassifier(BaseModel):
sentiment: str
user_reviews = '.
User_reviews.csv
User_reviews-1.csv
User_reviews-2.csv
User_reviews-3.csv
system_prompt = 'Classify the review as positive, neutral, or negative.'
results = so.infer(user_reviews, system_prompt, output_schema=ReviewClassifier)
Progress: 1% | 1/514,879 | Input tokens processed: 0.41m, Tokens generated: 591k
█░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░
Rapidly Prototype
Start small and iterate fast on your summarization workflows. Accelerate experiments by testing on a sample of your documents before committing to large jobs.
Scale Effortlessly
Scale your LLM workflows so your team can do more in less time. Process billions of tokens in hours with no infrastructure headaches or exploding costs.
Integrate Seamlessly
Connect Sutro to your existing LLM workflows. Sutro's Python SDK is compatible with popular data orchestration tools, like Airflow and Dagster.

Get Results in Hours, Not Days
Shorten development cycles and get feedback faster. Sutro is built to turn massive summarization jobs that would take days into tasks that complete in a fraction of the time.
Get results faster and reduce costs significantly by parallelizing your LLM calls through Sutro. Process billions of tokens without the exploding costs.
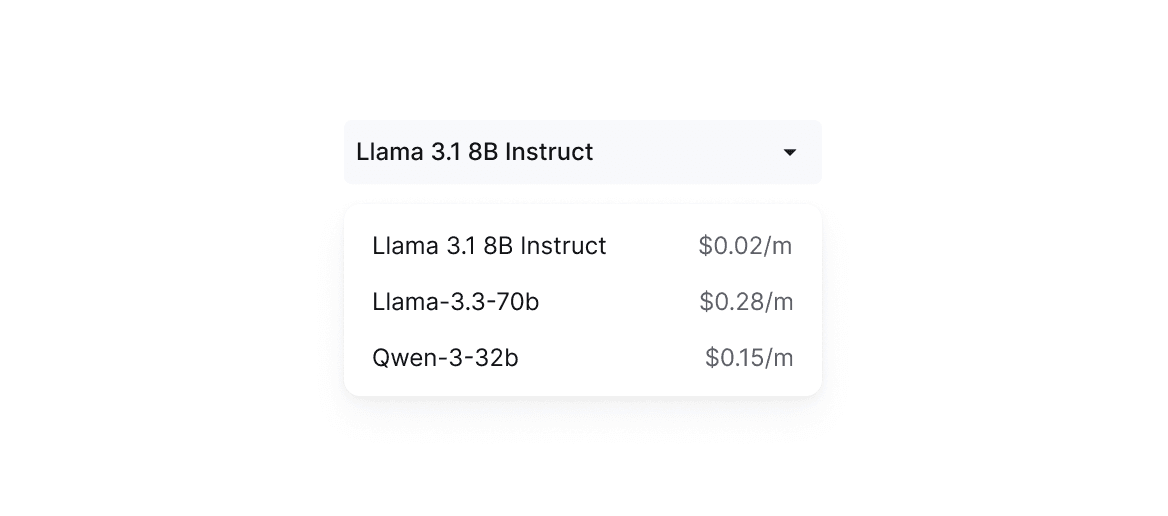
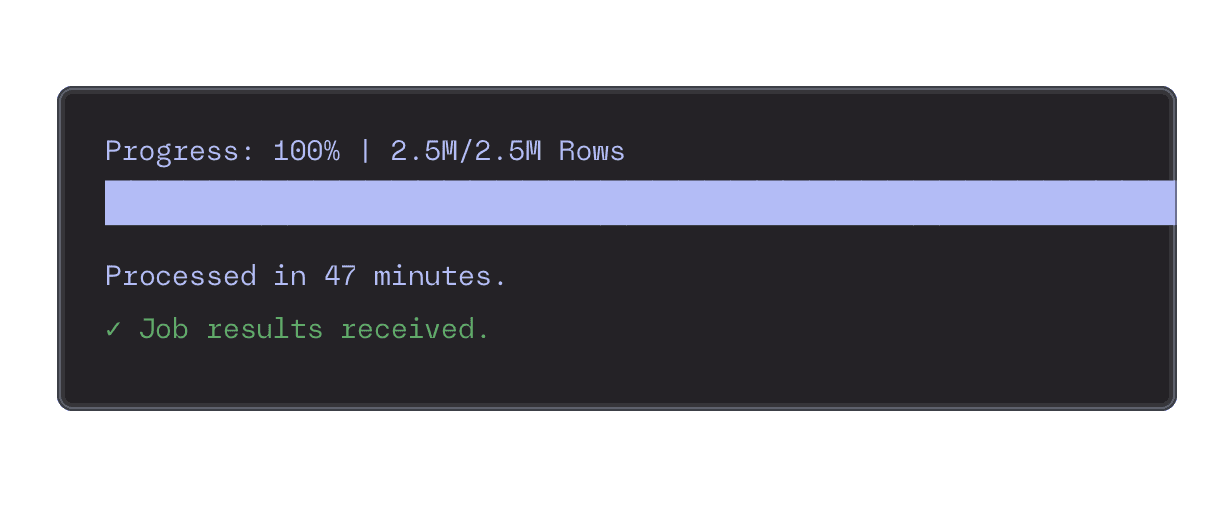
Scale Without Infrastructure Headaches
Confidently handle millions of requests at a time. Easily sift through thousands of product reviews or historical notes without the pain of managing your own infrastructure.
